
Are we measuring too much in Experience Sampling Methodology? A commentary on human “Screenomics”
This blogpost has been written by Jennifer Chen. Jennifer is a second-year PhD student of our research group working on her PhD project on guidelines for mixed-methods approaches and effective knowledge dissemination with her supervisors Melissa de Smet en Bennett Kleinberg.
Within the study of human behaviour there often is a trade-off between collecting a lot of information for accurate inferences, versus minimising the collection of personal and sensitive data (to reduce potential harm to the participant). In this blogpost I want to talk about recent methodological developments in the field of Experience Sampling Methodology, termed “Screenomics”. These developments seem to ignore the aforementioned trade-off, and instead collect a lot of personal data whilst also being unable to make accurate inferences.
But first, what is Experience Sampling Methodology?
Experience Sampling Methodology (ESM), also known as Ecological Momentary Assessment, is a form of intensive longitudinal assessment which involves multiple within-person measurement occasions. First formally developed as a dissertation project (Prescott et al., 1981), the method is used to gather empirical data on daily processes. Examples are data on the respondent’s thoughts, feelings, and psychopathological symptoms (Myin-Germeys et al., 2009) as well as their frequency, patterns, and fluctuations.
When implementing an ESM design, two practical decisions are choosing the amount of measurement occasions (within practice often called “beeps”), and the questions/items that are used in each beep. The measurement occasions are a function of the study duration and the number of beeps per day. Most studies seem to span over the duration of a week or two, though in some cases studies can span over the course of many months, up to a year.
Within every beep, a selection of questions are shown to the respondent. Many ESM designs start with asking some ‘contextual’ questions such as “Where are you now?”, “With who are you?” (Delespaul, 1995). This is often followed by Likert scale questions from existing quantitative questionnaires for mood (e.g., PANAS) and/or psychopathology (e.g., BDI-II).
A given strength of ESM is its aim for ecologically valid measurements, which is something particularly limited by psychological assessment methods such as laboratory observation, retrospective self-reports etc. A caveat to ESM however is that the assessment is considered labour-intensive and intrusive. This particularly is the case for study designs of long duration and/or with many beeps per day. Advancements in technology however have made it more feasible to acquire data in a less obtrusive manner.
Passive tracking of physiological and psychological states
Earlier versions of ESM included assessment through e-mail reminders and paging devices. This is now overshadowed by devices such as smartphones and wearable sensors. One aspect of such devices is that they allow for passive data collection. Passive data collection uses data that the devices were already keeping track of, therefore bypassing the need for written ESM items and active responses from the participants. Arguably, this relieves some of the participant burden associated with ESM research. In this case, participants ‘simply’ must read the informed consent form and allow for the sharing of their mobile data.
In the field of ESM, this method of data collection is also referred to as digital phenotyping. Digital phenotyping can be defined as the collection of the observable “digital footprint” left behind by a user’s digital devices. This includes the storage of data on for example location, screen time, the number of steps taken in a day, heart rate, sleep quality, activity on social networks, but also more technical aspects such as keyboard interaction, or the proximity between people’s Bluetooth devices (Oudin et al., 2023). Instead of constantly asking the participants “Where are you now?” and “Who are you with?”, this method can now collect the participant’s exact location as well as their proximity to others’ phones.
To me, it was quite concerning that a lot of personal data is being handled through this method. Especially when learning that some researchers use a combination of multiple (if not all) of these data sources for their studies. Yet it appears that this combination is useful within the field of health and illness (see: Insel, 2017). Altogether, these results may reveal patterns in human behaviour, which could be a data-driven approach to informing health care professionals about their patient’s status (Oudin et al., 2023).
Taking it a step further and introducing the next innovation: Screenomics
Recently however, researchers have taken digital phenotyping to the next level. I was informed of these developments through a keynote speaker at an ESM conference. In these developments, researchers have moved beyond collecting these built-in properties of smartphone devices (location, screen time etc.). Instead, they go the extra mile to measure everything that an individual is doing on their smartphone.
Introducing the Human Screenome Project, conducted at Stanford University (Reeves et al., 2020). The project’s name is a play on the intersection between digital phenotyping and the field of genomics. The investigators of the Human Screenome Project dub its purpose: “To understand how people use digital media [and] to produce and analyse recordings of everything people see and do on their screens”. The motivation behind this initiative is that whilst there almost definitely is an effect of digital media on mental and physical health, it is difficult to empirically prove so. Many studies on the impact of digital media rely on examining self-reported screen time of participants. Rather than collecting data on digital media use through the smartphone’s screen time, “Screenome” data involves taking screenshots of the smartphones of the participants, every five seconds.
Certainly, collecting screenshots every five seconds is a step further than digital phenotyping, as it involves collecting more information than what was being stored by one’s mobile phone already. Devices track a lot of things, but I hope they do not take screenshots of one’s activity every five seconds and save them for later examination (or if they do, (1) that is scary, and (2) where would they store all that data?).
What about participant privacy?
An obvious concern of collecting screenshots of participants’ phones is the invasion of privacy. In their commentary, the investigators of the Screenome project state:
“Through measures such as encryption, secure storage and de-identification, it is possible to collect screenomes with due attention to personal privacy. (All our project proposals are vetted by university institutional review boards, charged with protecting human participants.)”
It is good (and standard) to have encrypted and secure storage of the data. Reeves and colleagues (2020) however also mention having applied de-identification, whilst not providing a concrete strategy for doing so. It seems virtually impossible to sift through all the data manually and de-identify it. Indeed, another study using the Screenome method (Brinberg et al., 2021) claims to have not necessarily de-identified the screenshots. Rather, they used computational tools and machine learning methods to automatically extract features from the screenshots, without the screenshots being seen by the research staff. This however does not acknowledge the issues regarding data security of AI technologies and the possible re-identification through computational algorithms (Murdoch, 2021). It may therefore be somewhat misleading to state that Screenome data can be used confidentially, whilst at the same time using machine learning methods to extract “anonymous” data.
What about the purpose of this research?
The screenomes serve an ambitious purpose to “record and analyse everything people see and do on their screens” (Reeves et al., 2020), yet it lacks an actual specification for what the screenomes are meant to prove. The screenomes set out to be a measurement of smartphone use without solely relying on measuring the participants’ screen time and app use. Yet the only available findings are overviews of screenshots (see Figure 1) and descriptives such as the median use of the smartphone per day, moments during the day where phones are used, and engagement with different apps (e.g., of all the apps participant A engaged in, 53.2% were social media apps; Reeves et al., 2020). If you zoom in on an individual level, the overview of screenshots also boils down to a combination of screen time and app use (see Figure 1). Screenomes on their own therefore seem to tell very little. Or rather, it provides little extra information on top of what measures of screen time and app usage could not already provide.
Figure 1
Recording of 1 participant’s screenshots over a period of 21 days
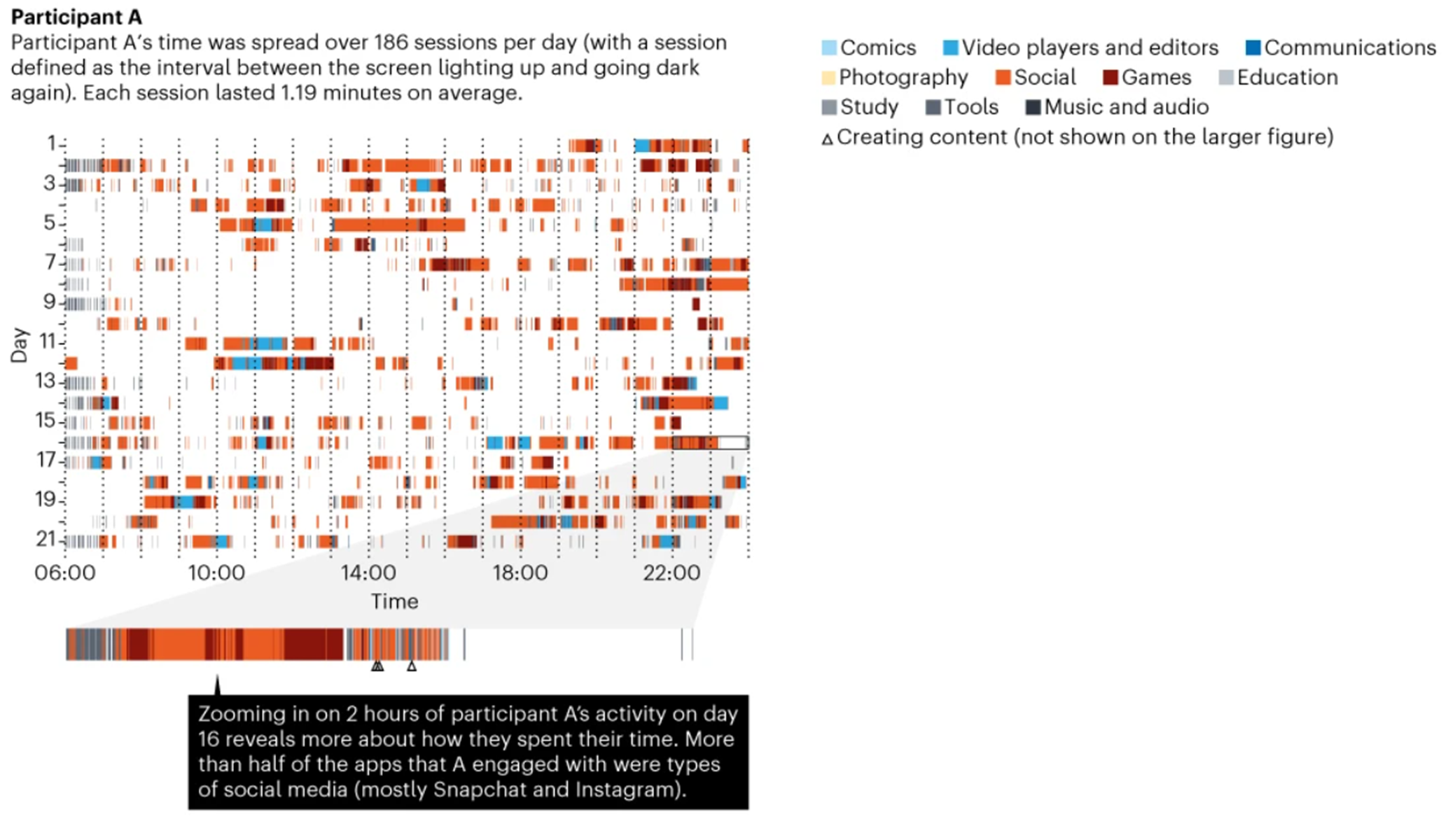
Source: Reeves et al. (2020). https://www.nature.com/articles/d41586-020-00032-5 section “Under the microscope”.
This begs the question: Why have the screenomes been collected in this manner, when at face value there does not seem to be an added benefit in doing so? The initial motivation behind screenomes was to empirically test the effect of digital media on mental and physical health. This attempt would however require additional data other than the screenshots (i.e., data on mental health, cognitive functioning), before being able to draw conclusions. I therefore believe that the screenomes as of now cannot prove anything beyond being able to collect a lot of data for the sake of having a lot of data.
Besides the lack of purpose behind collecting a lot of data (terabytes of data!), a problem remains in how a researcher should begin to analyse and meaningfully interpret the data. The investigators on this project acknowledge that “The particular pieces or features of the screenome that will be most valuable will depend on the question posed” and question “How can [we] extract meaning from data sets compromising millions of screenshots?” (Reeves et al., 2020).
The investigators themselves provide two solutions in their commentary. The first solution argues for the collaboration with companies such as Google and Amazon, considering that these companies already engage in some form of digital monitoring. This direction would call into question how independent such research really is, and whether the outcomes could be trusted. This morally questionable option would also exceed what the participants have given informed consent for. The second solution according to the authors is to ask the participants to “share their data with academics” (Reeves et al., 2020). Thereby again collecting more data than necessary, nor providing a concrete analytic plan.
Conclusion
This goes to show that the field of ESM is trying to utilize the latest technological advances to examine human behavior as realistically as possible, without the need of active participation from the participant’s side. Realistic measurement requires a lot of data, but how much data on our participants do we really need to conduct relevant research? I personally already draw the line at instances of digital phenotyping, where multiple variables are collected without needing to. The usage of screenomes therefore definitely goes too far.
The Screenome project is driven by technological novelty, but this novelty should not be equated with high quality research. Despite the project’s grandiosity, it has plenty of concerns related to the participant’s right to privacy and the actual meaningfulness of the collected data. Data needs to be collected with purpose, instead of gathering heaps of information and then seeing what we can do with it.
This has been more of an introduction and commentary on a sub-field of ESM. This blogpost by no means can comment on all the intricacies behind digital phenotyping and screenomes. In any case, this field of digital phenotyping in ESM is going to continue to develop (whether I personally like it or not). My wish is that with this blogpost more researchers become aware of developments in this field, and that we do not turn a blind eye to certain causes for concern with this data collection method.
References
Brinberg, M., Ram, N., Yang, X., Cho, M. J., Sundar, S. S., Robinson, T. N., & Reeves, B. (2021). The Idiosyncrasies of Everyday Digital Lives: Using the Human Screenome Project to Study User Behavior on Smartphones. Computers in Human Behavior, 114. https://doi.org/10.1016/j.chb.2020.106570
Delespaul, P. (1995). Assessing schizophrenia in daily life: The experience sampling method Maastricht University]. Universitaire Pers Maastricht. https://doi.org/10.26481/dis.19950504pd
Murdoch, B. (2021). Privacy and artificial intelligence: challenges for protecting health information in a new era. BMC Medical Ethics, 22(1), 122. https://doi.org/10.1186/s12910-021-00687-3
Myin-Germeys, I., Oorschot, M., Collip, D., Lataster, J., Delespaul, P., & Van Os, J. (2009). Experience sampling research in psychopathology: opening the black box of daily life. Psychological Medicine, 39(9), 1533-1547.
Oudin, A., Maatoug, R., Bourla, A., Ferreri, F., Bonnot, O., Millet, B., Schoeller, F., Mouchabac, S., & Adrien, V. (2023). Digital Phenotyping: Data-Driven Psychiatry to Redefine Mental Health. Journal of Medical Internet Research, 25, e44502. https://doi.org/10.2196/44502
Prescott, S., Csikszentmihalyi, M., & Graef, R. (1981). Environmental effects on cognitive and affective states: The experiential time sampling approach. Social Behavior and Personality: An International Journal, 9(1), 23-32. https://doi.org/10.2224/sbp.1981.9.1.23
Reeves, B., Robinson, T., & Ram, N. (2020). Time for the Human Screenome Project. Nature, 577(7790), 314-317. https://doi.org/10.1038/d41586-020-00032-5