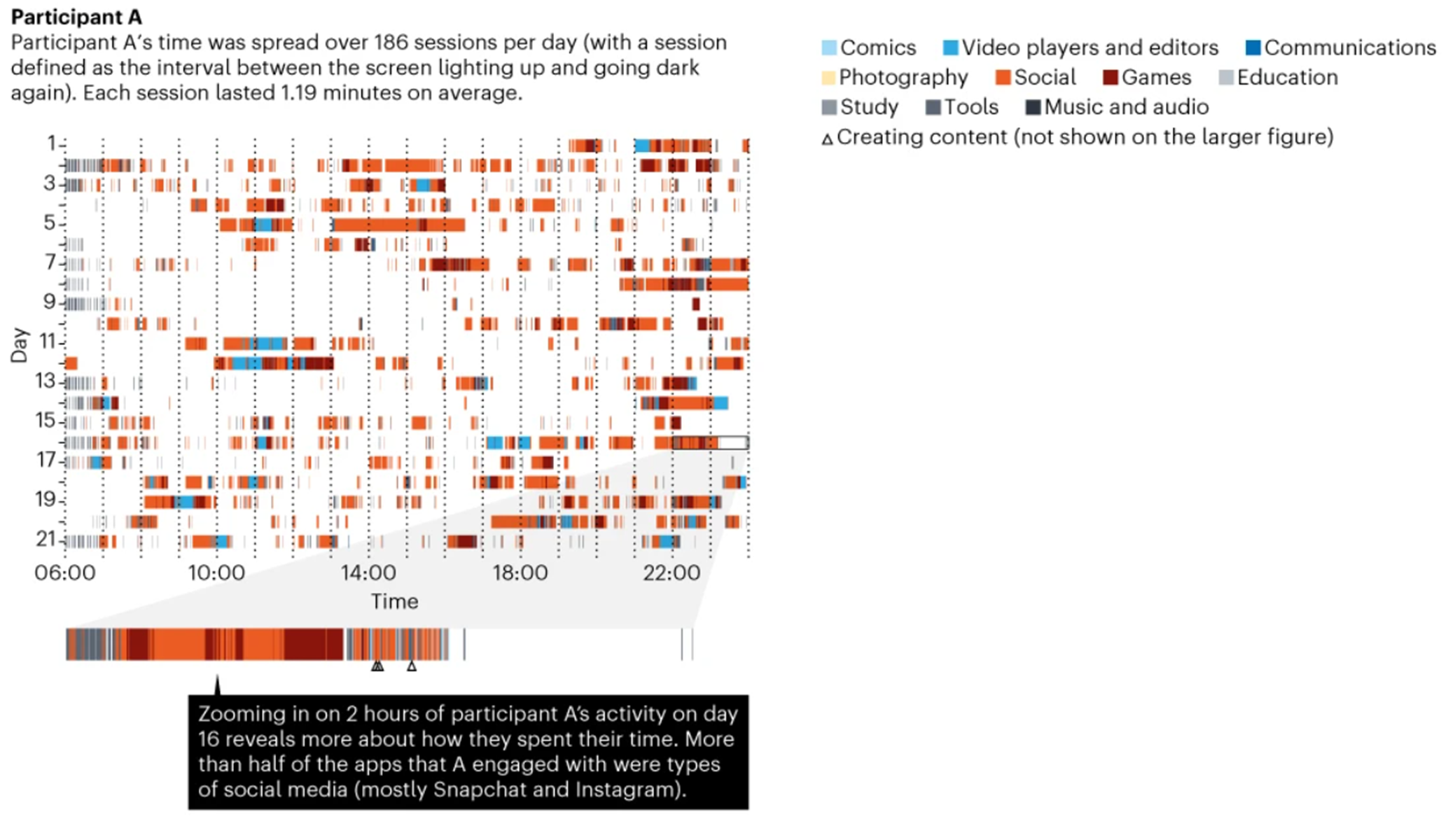
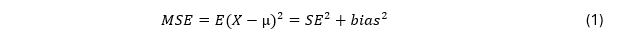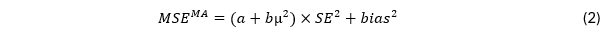Checking for Statistical Errors in Primary Studies: A Way to Improve Meta-Analytic Evidence?
This blogpost was written by dr. Olmo van den Akker. He is a postdoc in our department working on two projects: a systematic review of studies that simulate p-hacking, and a randomized controlled trial of results-blind peer review. Next to that, he is also a postdoc at the QUEST Center of Responsible Research in Berlin, where he aims to improve the transparency and ethics of studies that use existing health data. Before his postdoc roles, he did his PhD at our department on the effectiveness of preregistration in psychology.
Introduction
Meta-analyses are often considered to be at the top of the evidence hierarchy, but they are only as good as the primary studies they include. The logic of “garbage in, garbage out” has been discussed in evidence synthesis circles for decades (Eysenck, 1978) but assessing ‘quality’ is by no means straightforward (Shadish, 1989). Quality checks in meta-analyses rarely go beyond risk-of-bias assessments, which often fail to capture important aspects of study quality (Frampton et al., 2022; Wilkinson et al., 2025). Indeed, these assessments operate on the assumption that studies are both free from errors and based on genuine data. As a result, meta-analyses can include results from low-quality studies that have little to no evidentiary value or may even bias the overall meta-analytic estimate (Simonsohn et al., 2022). During a recent hackathon, we discussed this problem and tried to come up with actionable solutions to more efficiently identify and remove low-quality studies from meta-analyses.
Rather than attempting a comprehensive quality assessment, we wanted to try an (extremely narrow) proxy for research quality: statistical inconsistencies. While statistical inconsistencies have several possible origins, including typos and rounding errors, they can invalidate a study’s results, and mounting inconsistencies may also signal inadequate rigor in the overall research process. A growing ecosystem of automated error-checking tools exists, some of which are widely known and relatively easy to use. The main goal of our team during the hackathon was to explore whether a minimal, standardized error-screening step to identify and remove studies with statistical inconsistencies is feasible and can change the evidentiary base of meta-analyses.
What exactly did we do?
Over the course of our 3-day hackathon, our plan was to:
1. Select automated error checking tools we thought would be easiest to implement and most relevant for psychological research.
2. Try out these tools for one small meta-analysis - Note: we stopped after this step.
3. Draft a study protocol to apply these tests at scale.
Error checking tools
Readers might already be aware of tools like statcheck (Nuijten & Epskamp, 2024) and GRIM (Granularity-Related Inconsistency of Means; Brown & Heathers, 2016). These tools provide checks to identify inconsistencies in reported statistics. Statcheck uses the reported degrees of freedom and test statistic to recompute the p-value and checks whether that recomputed p-value is consistent with the p-value that is actually reported. GRIM checks whether a reported arithmetic mean of integer data (e.g., Likert scale responses) is mathematically possible for a given sample size. Research shows that erroneously reported statistics are common in the published literature. For example, using statcheck, Nuijten et al. (2016) found that roughly half of the articles with statistics they examined contained p-values that were inconsistent with the reported degrees of freedom. In 1 in 8 papers, the recalculated p-value even led to a change of the statistical conclusion. Similarly, in an analysis of 71 papers, GRIM flagged about half as containing at least one mathematically impossible mean (Brown & Heathers, 2016). Given their empirical effectiveness at identifying errors and their general familiarity arising from articles in journals like Nature and Science (Chawla, 2023; Marcus & Oransky, 2018), we chose statcheck and GRIM for our test case. Other tools that could potentially be used for identifying errors or statistical anomalies are, for instance, GRIMMER (Anaya, 2016), SPRITE (Heathers et al., 2018), RIVETS (Brown & Heathers, 2019), TIVA (Schimmack, 2015), TIDES (Hussey et al., 2024), and the Carlisle Test (Carlisle, 2012; 2017).
An example
To show what a standardized error-screening step for meta-analyses could look like in practice, we used statcheck and GRIM to exclude primary studies with errors from a small meta-analysis on the effect of self-control depletion on unethical behavior (from Bellé & Cantarelli, 2017). We chose this meta-analysis because it only includes 8 studies from 4 papers, and because it features studies from several influential authors. Additionally, one of the authors of this blog post is also represented with a paper (Van ‘t Veer et al., 2014).
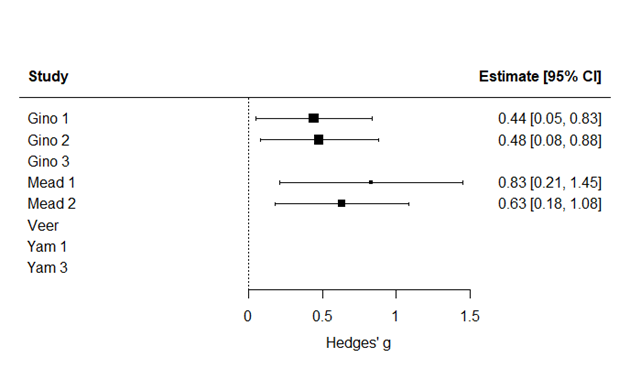
Statcheck ended up finding three statistical inconsistencies: one in Van ‘t Veer et al. (2014) and two in Yam et al. (2014), where one inconsistency was related to Study 1 and the other consistency to Study 3. GRIM found an inconsistency in the third study of Gino et al. (2011). By removing these four primary studies, the meta-analytic effect size went from 0.22 to 0.55. This big increase stems from the fact that three of the four omitted studies had a negative effect, leaving only positive effects to drive the new meta-analytic estimate. In Figure 1 and Figure 2 you can find the forest plots with and without the primary studies, respectively. The data and code for this small pilot study can be found in this OSF repository.
Figure 1. The original meta-analysis with all primary studies (g = 0.22)
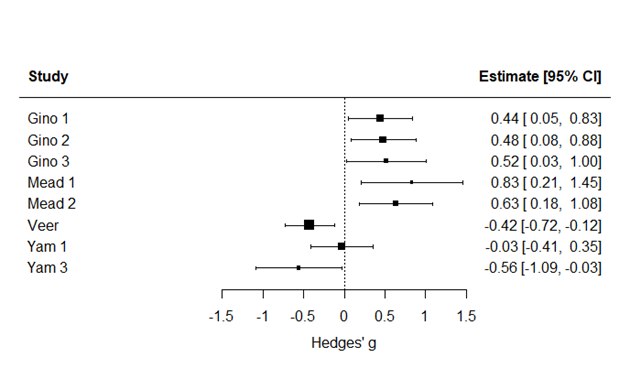
Figure 2. The meta-analysis without the primary studies with a statistical inconsistency (g = 0.55)
Scalability as the main bottleneck
Although applying the proposed checks to a single paper is feasible, applying them systematically across multiple studies turned out to be more difficult than we thought.
For statcheck, extracting inconsistencies from a paper via the web app takes only a few clicks. However, the resulting output does not indicate to which study within a multi-study paper a given inconsistency belongs. As a result, researchers must manually inspect the paper to determine whether to which study the flagged inconsistency pertains. It is important to do the analysis on a study level instead of the paper level because multi-study papers typically include more statistics than single-study papers, heightening the chance of inconsistencies and omission. In addition, as acknowledged by its creator (Nuijten, 2025) statcheck does not reliably extract all test statistics: results are often missed because they are not reported in strict APA style, χ² statistics are frequently misidentified due to parsing issues with the χ symbol, and non-parametric tests are generally unsupported (Böschen, 2024). While some of these limitations could in principle be mitigated (e.g., by using the metacheck R package; https://www.scienceverse.org/metacheck), statcheck’s circumscribed uses make its implementation in this automated screening process currently complex at scale. This is understandable given that statcheck was not originally intended for this type of application.
A GRIM consistency check requires you to manually extract the means and corresponding sample sizes from a paper. Once that is done, the idea behind it is quite simple: if a sample consists of a certain number of individuals, the mean of any integer-valued variable (such as age) must fall on a specific value determined by that sample size. For example, a mean age of 30.17 is mathematically impossible with n = 2, whereas values such as 30.5 or 40 are possible. This logic generalizes to larger samples, but its practical usefulness declines as sample size increases. As its creators explain, once the sample size exceeds 100 observations, the mean must be reported to at least three decimal places for GRIM to be able to detect inconsistencies at all (Brown & Heathers, 2016). Because sample sizes in empirical studies can exceed this range, and because means are typically reported to only two decimal places (according to APA guidelines), GRIM sometimes lacks the resolution needed to identify inconsistencies.
A second issue is that GRIM can only be used on means that come from integer data (e.g., Likert data or age in years; Brown & Heathers, 2016). This makes these checks difficult to automate, as meta-analysts must first determine, often via a manual decision process, whether a given mean is eligible for testing at all.
Third, there are currently no easy ways to automate the extraction of the relevant values from a paper. For example, means and standard deviations are often presented in tables and/or not presented alongside the sample size, which is often only presented once at the beginning of the methods section. Sometimes it is hard to know which sample size is relevant for a given analysis because of exclusions and missing data. This makes life hard for extraction tools like metacheck and for inclusion in our screening procedure. However, it must be noted that meta-analysts do typically look up and extract means, standard deviations, and sample sizes manually already. To the extent that this is already the case, implementing GRIM would be correspondingly easier.
Finally, carrying out GRIM at scale can be challenging, for one because Anaya’s GRIM calculator (https://www.prepubmed.org/grim_test) does not support batch processing. The scrutiny R package (Jung, 2025), which can be used to apply GRIM in R at scale, users need to explicitly enter the reported values as character strings to ensure information about trailing zeros is preserved. This adds some overhead but is necessary to accurately convey the decimal precision of the reported numbers. As for the scrutiny web app (https://errors.shinyapps.io/scrutiny), we were unable to properly load data files reliably at the time, but it seems to properly work now after some updates by scrutiny’s developer, Lukas Jung. With further refinement, implementing GRIM (and its cousin GRIMMER) at scale should become increasingly feasible.
In all, however, we realised that the effort currently required for meta-analysts to conduct error checks may be greater than we had initially anticipated. This is also the reason we decided not to begin developing a protocol for error screening at a larger scale. At least for now, reliable use of error-checking tools would likely require access to articles in structured formats (e.g., XML), or extensive additional manual assessments of papers.
Even so, we believe that these tools have considerable potential. At the same time, their promise should not be overstated: even in an optimistic future, where automated checks become extremely easy and fast to perform at scale, they still would not replace the broader suite of tools needed for thorough quality assessment. In our view, human judgment will always be a necessary part of quality assessment more broadly. Tools such as INSPECT-SR (Wilkinson et al., 2025), a consensus-based research integrity assessment tool, and more interpretative judgments about internal validity or conceptual soundness, all address dimensions of “quality” that automated tools are not well positioned to capture. Automated error checking may become one valuable piece of the puzzle, but they are not sufficient on their own. For these kinds of error-detection tasks, having a human-in-the-loop is always responsible practice, as is also emphasized by the developers of these tools.
Acknowledgments
Many thanks to Beth Clarke, Sandra Grinschgl, Lukas Jung, Jamie Cummins, and Ian Hussey (University of Bern), Daniel Hamilton (Monash University), Elizabeth Tenney (University of Utah), Anna van 't Veer (Leiden University), and Michèle Nuijten (Tilburg University) for their feedback on this blog post, and big thanks to Simine Vazire (University of Melbourne) for making the hackathon possible in the first place.
References
Anaya, J. (2016). The GRIMMER test: A method for testing the validity of reported measures of variability (PeerJ Preprints). https://doi.org/10.7287/peerj.preprints.2400v1
Bellé, N., & Cantarelli, P. (2017). What causes unethical behavior? A meta‐analysis to set an agenda for public administration research. Public Administration Review, 77(3), 327-339.
Böschen, I. (2024). statcheck is flawed by design and no valid spell checker for statistical results. https://arxiv.org/abs/2408.07948.
Brown, N. J. L., & Heathers, J. (2019, October 24). Rounded Input Variables, Exact Test Statistics (RIVETS). https://doi.org/10.31234/osf.io/ctu9z
Brown, N. J. L., & Heathers, J. A. J. (2016). The GRIM test: A simple technique detects numerous anomalies in the reporting of results in psychology. Social Psychological and Personality Science, 7(6), 567–574.
https://doi.org/10.1177/1948550616673876
Carlisle, J. B. (2012). The analysis of 168 randomised controlled trials to test data integrity. Anaesthesia, 67(5), 521–537. https://doi.org/10.1111/j.1365-2044.2012.07128.x
Carlisle, J. B. (2017). Data fabrication and other reasons for non-random sampling in 5087 randomised, controlled trials in anaesthetic and general medical journals. Anaesthesia, 72(8), 944–952. https://doi.org/10.1111/anae.13938
Chawla, D. S. (2023, March 15). ‘Spell-checker for statistics’ reduces errors in the psychology literature. Nature. https://doi.org/10.1038/d41586-023-00788-6
Eysenck, H. J. (1978). An exercise in mega-silliness. American Psychologist, 33(5), 517–517.
https://doi.org/10.1037/0003-066X.33.5.517
Frampton, G., Whaley, P., Bennett, M. et al. Principles and framework for assessing the risk of bias for studies included in comparative quantitative environmental systematic reviews. Environ Evid 11, 12 (2022). https://doi-org.tilburguniversity.idm.oclc.org/10.1186/s13750-022-00264-0
Gino, F., Schweitzer, M. E., Mead, N. L., & Ariely, D. (2011). Unable to resist temptation: How self-control depletion promotes unethical behavior. Organizational Behavior and Human Decision Processes, 115(2), 191–203.
https://doi.org/10.1016/j.obhdp.2011.03.001
Heathers, J. A. J., Anaya, J., van der Zee, T., & Brown, N. J. L. (2018). Recovering data from summary statistics: Sample Parameter Reconstruction via Iterative TEchniques (SPRITE) (PeerJ Preprints). https://doi.org/10.7287/peerj.preprints.26968v1
Hussey, I., Norwood, S. F., Cummins, J., Arslan, R. A., & Elson, M. (2024). Truncation-Induced Dependency in Summary Statistics (TIDES): A method to check for inconsistencies in reported summary statistics for truncated data. https://github.com/ianhussey/tides
Schimmack, U. (2015, May 13). The test of insufficient variance (TIVA): A new tool for the detection of questionable research practices [Blog post]. Replicability-Index. https://replicationindex.com/2015/05/13/the-test-of-insufficient-variance-tiva-a-new-tool-for-the-detection-of-questionable-research-practices-2/
Shadish, W. R. (1989). The perception and evaluation of quality in science. Cambridge University Press.
Simonsohn, U., Simmons, J., & Nelson, L. D. (2022). Above averaging in literature reviews. Nature Reviews Psychology, 1(10), 551-552.
Marcus, A., & Oransky, I. (2018, February 14). Meet the ‘data thugs’ out to expose shoddy and questionable research. Science. https://www.science.org/content/article/meet-data-thugs-out-expose-shoddy-and-questionable-research
Nuijten, M. B. (2025, January 9). Statcheck does what it is designed to do: a reply to Böschen (2024). https://doi.org/10.31234/osf.io/xyfjz
Nuijten, M. B. & Epskamp, S. (2024). statcheck: Extract statistics from articles and recompute p-values. R package version 1.5.0. Web implementation at https://statcheck.io.
Nuijten, M. B., Hartgerink, C. H. J., van Assen, M. A. L. M., Epskamp, S., & Wicherts, J. M. (2016). The prevalence of statistical reporting errors in psychology (1985–2013). Behavior Research Methods, 48(4), 1205–1226.
https://doi.org/10.3758/s13428-015-0664-2
Jung, L. (2025). scrutiny: Error Detection in Science. R package version 0.6.1, https://lhdjung.github.io/scrutiny/.
Van ’t Veer, A. E., Stel, M., & van Beest, I. (2014). Limited capacity to lie: Cognitive load interferes with being dishonest. Judgment and Decision Making, 9(3), 199–206
Wilkinson, J., Heal, C., Flemyng, E., Antoniou, G. A., Aburrow, T., Alfirevic,Z., ... & Kirkham, J. J. (2025). INSPECT-SR: a tool for assessing trustworthiness of randomised controlled trials. medRxiv.
Yam, K. C., Chen, X. P., & Reynolds, S. J. (2014). Ego depletion and its paradoxical effects on ethical decision making. Organizational Behavior and Human Decision Processes, 124(2), 204-214.